Introduction
I was searching on Google on SQL Server Replication, which I planning to implement one of my current project and found this great article on code project....There are a lot of people who subscribe for magazines like readers digest or India today or get organizational news update every month in their mail box. Information about the latest organizational/national development is communicated over these email/magazines. The information is directly dropped in mail box or at the door step. We simply need to subscriber for the desired magazine or mailer. Similarly the replication feature in MS SQL Server moves the data from a remote server to our local server boxes via publications and subscriptions mechanism. There are various reasons and scenario where replications can be considered a very strong tool for data relay. We could consider replication for,
- Getting the data closer to the user, consider a server stationed in Germany and since the business also operates at Bangalore in India we need the data quite frequently. Now every time we need the data from the Products or Sales table we need to use a linked server, connect to the German Server and pull the data. This will have impacts like:
- We need to rely heavily on the network connectivity each time we pull the data.
- Secondly the source server will have to bear the load of data reads.
- Also these ad-hoc queries might create conflicts if there is any exclusive lock on a record on account of any transaction taking place on the source data. Further to this, the ad-hoc pull queries will run for a really long time in this case eating up network bandwidth and also causing unnecessary load on the source.
- And if the data is to be pulled on a regular basis this ad-hoc queries seem really out of place option. Consider replication for removing impacts of heavy read intensive operations like report generation etc. Replication is a very good option when the desired data is simply read only and the update to the source is not intended.
- Consider replication when server pulling the data intends to own the pulled data i.e. make changes to the pulled version without impacting the source. Replication provides the desired autonomy to the subscriber.
- Consider replication when server pulling the data intends to own the pulled data i.e. make changes to the pulled version without impacting the source. Replication provides the desired autonomy to the subscriber.
Getting Started with Replication
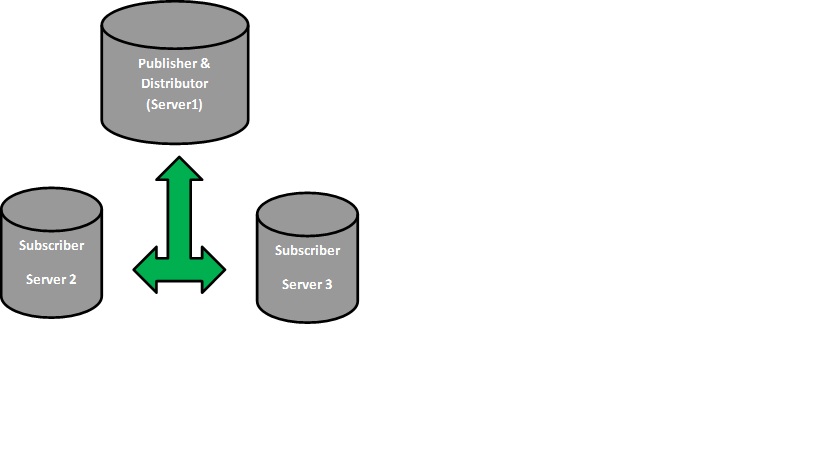
Before getting into the details on how to setup replication let’s try to get acquainted with the terms involved with this exciting feature. Replication traditionally takes the Publisher/Subscriber analogy. It’s quite similar to the magazine example. For any magazine there is a publisher who publishes information in the form ofarticles. Once the magazine (which is collection of article and is called publication) is published there needs to be a distributor who will distribute it to people like you and me who are actually the subscribers. This forms the standard of the entire Publisher/Subscriber cycle. But there could be changes in the setup like there is a publisher who also acts as distributor or there could be a distributor who is also a subscriber. The key terms are:
Article: The article is the information that is going to be replicated. It could be a table, a procedure or a filtered table etc.
Publisher: The publisher is the database on the source server which is actually replicating the data. Thepublication which is collection of articles (various objects in the database) is published by the publisher.
Distributor: The distributor can be considered as the delivery boy who brings the publications to the subscriber. The distributor could himself be a publisher or a subscriber.
Subscriber: Subscriber is the end receiver of the publication who gets the data in the form of subscriptions. The changes published are propagated to all the subscribers of the publications through the distributor. The subscriber simply has to create a subscription on the publication from its end to receive the data.
There are various types of replication:
- Transactional Replication
- Transactional Replication with Updatable Subscriptions
- Snapshot Replication
- Merge replication
Configuring a Distributor
Before trying to get insights about each of the replications and how to configure it, it’s important to setup a distributor.
Select the server which is to act as the distributor and the right click on the replication folder and then click configure Distribution.
This will lead to the below screen, click next.
The next screen as below will as to either configure the current server as the Distributor or connect to the different desired server and configure it to be a distributor. Let’s select the current server and click next.

The next screen point to the folder path where the snapshots of the publications will be kept by the snapshot agent, we will keep the default value and click next. You can also specify the network folder if you have....
How to create network folder : http://www.dummies.com/how-to/content/how-to-map-a-network-folder-in-windows-7.html

The Next screen configures the Distribution database its data (.MDF) and Log (.ldf) files. Bear in mind once the distribution has been configured on a server, the system databases will have an additional database added to it “Distribution”. Click next.

On clicking next it brings you to the screen where you can add all the servers which will be the publishers and use the currently being configured distributor to distribute its publications. By default the current server will be added as the publisher once could add more servers. Click next.

Click next on the below screen and proceed.

his will bring you to the last screen which will have the summary of the configurations. Click finish to complete the Distributor configuration.

Once you click on Finish, you will see new database with name "distribution" and couple of jobs are created under the job...


If you want to remove the existing distribution, you can right click on the "Replication" node and click on "Disable Publishing and Distribution..."

And click on Finish button....
Transactional Replication
In the transactional replication the transactions occurring on the published articles from the publisher are forwarded on to the distributor who in turn replicates the same and commits them on the subscribers. Subscribers can use this data for read only purposes. As transactions are small items to publish the latency for transactional replication is very low. As far as the autonomy is concerned as the data is read only type each of the subscribers cannot update the data and hence there is absolutely no autonomy in this type of replication.
Suppose there is a ticket booking web site, all the tickets booked are centrally stored in the database hosted at New Delhi. There are distribution centers in every city in the country where the bookings are received and the booked ticket shipped at the addresses provided. All the tickets booked from Hyderabad needs to be shipped to the respective customers. The Hyderabad distribution center could setup a filtered (get bookings for Hyderabad only) transactional replication so that every new booking (transaction) is replicated to their center with minimal delay (almost immediately). They need a read only access to the replicated data so transactional replication fits the bill. They could dispatch the booked ticket ASAP with transactional replication setup.
Key facts of transactional replication:
- As replication happens on a transaction, the latency of replication is very low.
- The subscription is read only, hence there almost no autonomy for the subscribers.
Creating Publisher for the Transnational Replication
Right click on the "Local Publication" under "Replication" folder on the SQL Server instance which is going to act like publisher. and then click on "New Publication"

Click on "Next"

Select the database for which you want to publish... In this case I have selected "POS_DataAnalysis" and click on "Next"

Click on the "Transnational Replication" and click on Next...

Expand the "Table" node and select those tables which one you want to publish... Note: It allow to publish those tables, have primary key defined... Marked in read are not eligible for replication as don't have primary key...

click on Next

if you want to add any filter for the selected table you can add here... for now lets publish all the row... so click on "Next"

click on the first check box and click Next...

select the snapshot agent security and click on next

click on next...

Enter the publication name and click on Finish button...

Now we are done with Publisher... lets verify

Creating Subscriber for the Transnational Replication
Right click on "Local Subscriptions" under "Replication" node in the SQL Server , act as subscription and click on "New Subscription"

click on "Next"

Select the publisher name and click on Next

select the "Push Subscription" and click on next...

select the database and click on next...

select the SQL Server authentication and click on finish

Once it complete sucess fully you can see the




















